巧用VideoSubFinder加Umi-OCR提取视频硬字幕转为SRT外挂字幕by ADMIN on 11 9 月,2023
有时候我们找到的电影资源,总是不尽人意,比如我最近找到的《黄河大侠》电影,情况就比较特殊,有字幕的版本有广告,而且还是硬字幕画质也低,没广告水印的版本,又没有字幕,而且找遍了全网也没有找到外挂字幕,所以决定将有字幕版中的硬字幕提取出来,做成外挂字幕。
一:
首先下载两个软件备用,这两个软件均为解压即可使用,不需要安装。Umi-OCR 文字识别工具准确度较高,比tesseract-ocr更优秀
1. VideoSubFinder 下载地址:https://sourceforge.net/projects/videosubfinder/files
2. Umi-OCR 文字识别工具 下载地址:https://github.com/hiroi-sora/Umi-OCR/releases
二:
1.打开VideoSubFinder,点击菜单栏的File,选择Open Video(两个均可)

2.在软件上半左边区域里,可以拖动图中的四个线条,选择控制硬字幕所在视频的区域

3.在软件下半区域里,确保在Search选项卡,begin time是设置字幕开始时间,end time是设置字幕结束时间,一定要先点击clear folders 清除历史文件,然后再点击run search 开始搜索有字幕的画面帧,软件会自动将有字幕的画面保存为图片到VideoSubFinder_x64\RGBImages目录,耐心等待进度完成。完成后一定不要关闭VideoSubFinder软件。

三:
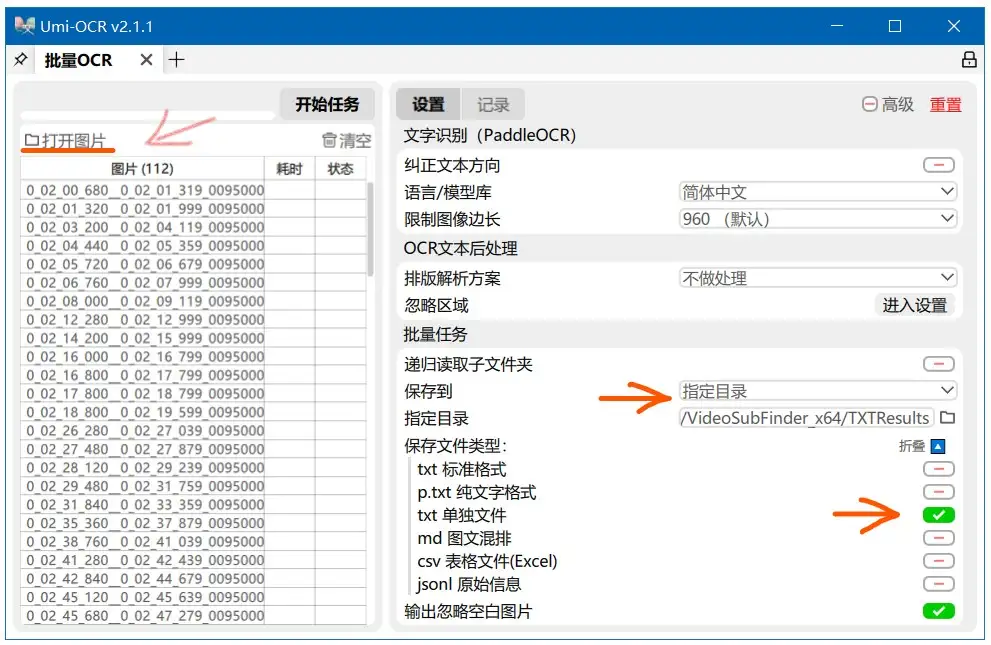
1.打开Umi-OCR 文字识别工具,选择左边的“批量OCR”,在新打开的页面右边进行如下设置,“保存文件类型”处只需要勾选“txt独立文件”,保存到“指定目录”填入“VideoSubFinder根目录下的TXTResults文件夹”,“语言/模型库”按需设置。
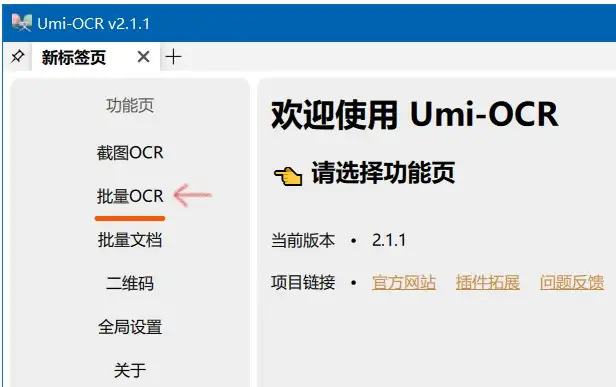
2.点击左边的“打开图片”图标,在打开的窗口里指向 VideoSubFinder文件夹下的/RGBImages目录,选择目录下的所有图片文件打开,然后点击软件右上角的”开始任务”,此时Umi-OCR 文字识别工具会将RGBImages目录下的图片文件转换成独立的文本文件,保存在TXTResults目录下,耐心等待直到任务完成。
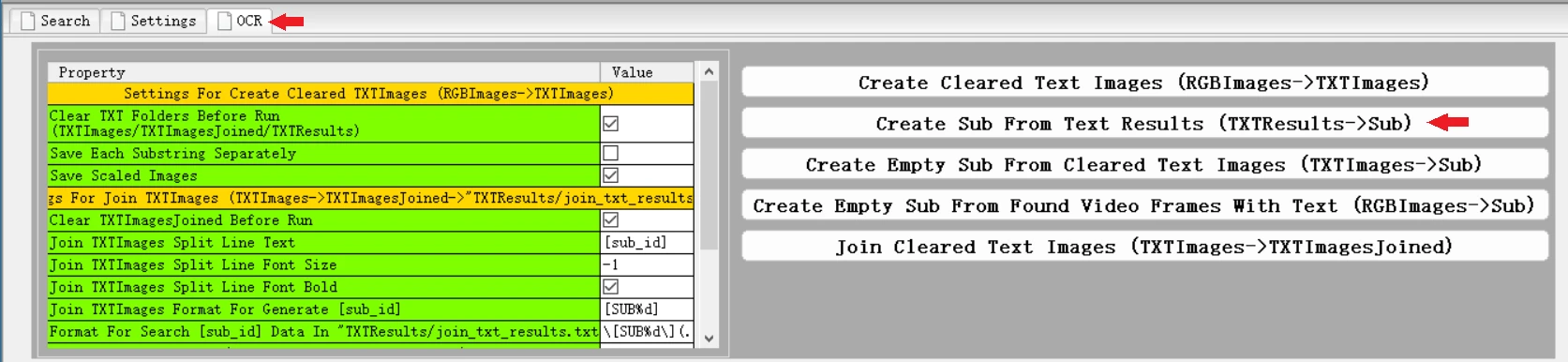
四:切换到VideoSubFinder软件,切换到OCR选项卡,点击“create sub from text results (TXTResults->Sub)”生成srt字幕文件并保存。
五:可以使用subtitle edit 或者aegisub等字幕软件打开srt字幕文件修改错别字